Research Highlights

Depthtrack: Unveiling the power of rgbd tracking
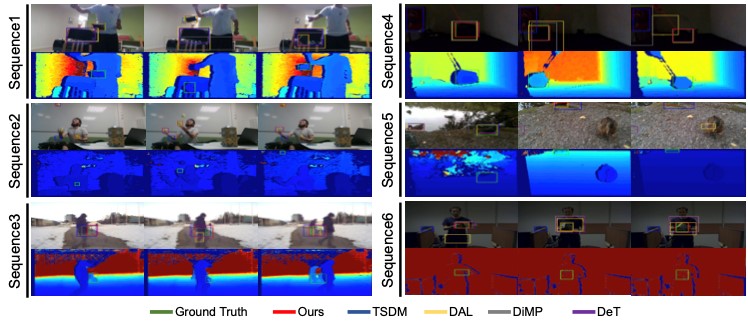
RGBD (RGB plus depth) object tracking is gaining momentum as RGBD sensors have become popular in many application fields such as robotics. However, the best RGBD trackers are extensions of the state-of-the-art deep RGB trackers. They are trained with RGB data and the depth channel is used as a sidekick for subtleties such as occlusion detection. This can be explained by the fact that there are no sufficiently large RGBD datasets to 1) train “deep depth trackers” and to 2) challenge RGB trackers with sequences for which the depth cue is essential. This work introduces a new RGBD tracking dataset - DepthTrack - that has twice as many sequences (200) and scene types (40) than in the largest existing dataset, and three times more objects (90). In addition, the average length of the sequences (1473), the number of deformable objects (16) and the number of annotated tracking attributes (15) have been increased. Furthermore, by running the SotA RGB and RGBD trackers on DepthTrack, we propose a new RGBD tracking baseline, namely DeT, which reveals that deep RGBD tracking indeed benefits from genuine training data. The code and dataset is available at https://github.com/xiaozai/DeT.

Prompting for Multi-Modal Tracking
Multi-modal tracking gains attention due to its ability to be more accurate and robust in complex scenarios compared to traditional RGB-based tracking. Its key lies in how to fuse multi-modal data and reduce the gap between modalities. However, multi-modal tracking still severely suffers from data deficiency, thus resulting in the insufficient learning of fusion modules. Instead of building such a fusion module, in this paper, we provide a new perspective on multimodal tracking by attaching importance to the multi-modal visual prompts. We design a novel multi-modal prompt tracker (ProTrack), which can transfer the multi-modal inputs to a single modality by the prompt paradigm. By best employing the tracking ability of pre-trained RGB trackers learning at scale, our ProTrack can achieve high-performance multi-modal tracking by only altering the inputs, even without any extra training on multi-modal data. Extensive experiments on 5 benchmark datasets demonstrate the effectiveness of the proposed ProTrack.

Towards Generic 3D Tracking in RGBD Videos: Benchmark and Baseline
Tracking in 3D scenes is gaining momentum because of its numerous applications in robotics, autonomous driving, and scene understanding. Currently, 3D tracking is limited to specific model-based approaches involving point clouds, which impedes 3D trackers from applying in natural 3D scenes. RGBD sensors provide a more reasonable and acceptable solution for 3D object tracking due to their readily available synchronised color and depth information. Thus, in this paper, we investigate a novel problem: is it possible to track a generic (class-agnostic) 3D object in RGBD videos and predict 3D bounding boxes of the object of interest? To inspire research on this topic, we newly construct a standard benchmark for generic 3D object tracking, ‘Track-it-in-3D’, which contains 300 RGBD video sequences with dense 3D annotations and corresponding evaluation protocols. Furthermore, we propose an effective tracking baseline to estimate 3D bounding boxes for arbitrary objects in RGBD videos, by fusing appearance and spatial information effectively. Resources are available on https://github.com/yjybuaa/Track-it-in-3D.

Benchmarks for Corruption Invariant Person Re-identification
When deploying person re-identification (ReID) model in safety-critical applications, it is pivotal to understanding the robustness of the model against a diverse array of image corruptions. However, current evaluations of person ReID only consider the performance on clean datasets and ignore images in various corrupted scenarios. In this work, we comprehensively establish five ReID benchmarks for learning corruption invariant representation. In the field of ReID, we are the first to conduct an exhaustive study on corruption invariant learning in single- and cross-modality datasets, including Market-1501, CUHK03, MSMT17, RegDB, SYSU-MM01. After reproducing and examining the robustness performance of 21 recent ReID methods, we have some observations: 1) transformer-based models are more robust towards corrupted images, compared with CNN-based models, 2) increasing the probability of random erasing (a commonly used augmentation method) hurts model corruption robustness, 3) cross-dataset generalization improves with corruption robustness increases. By analyzing the above observations, we propose a strong baseline on both single- and cross-modality ReID datasets which achieves improved robustness against diverse corruptions.
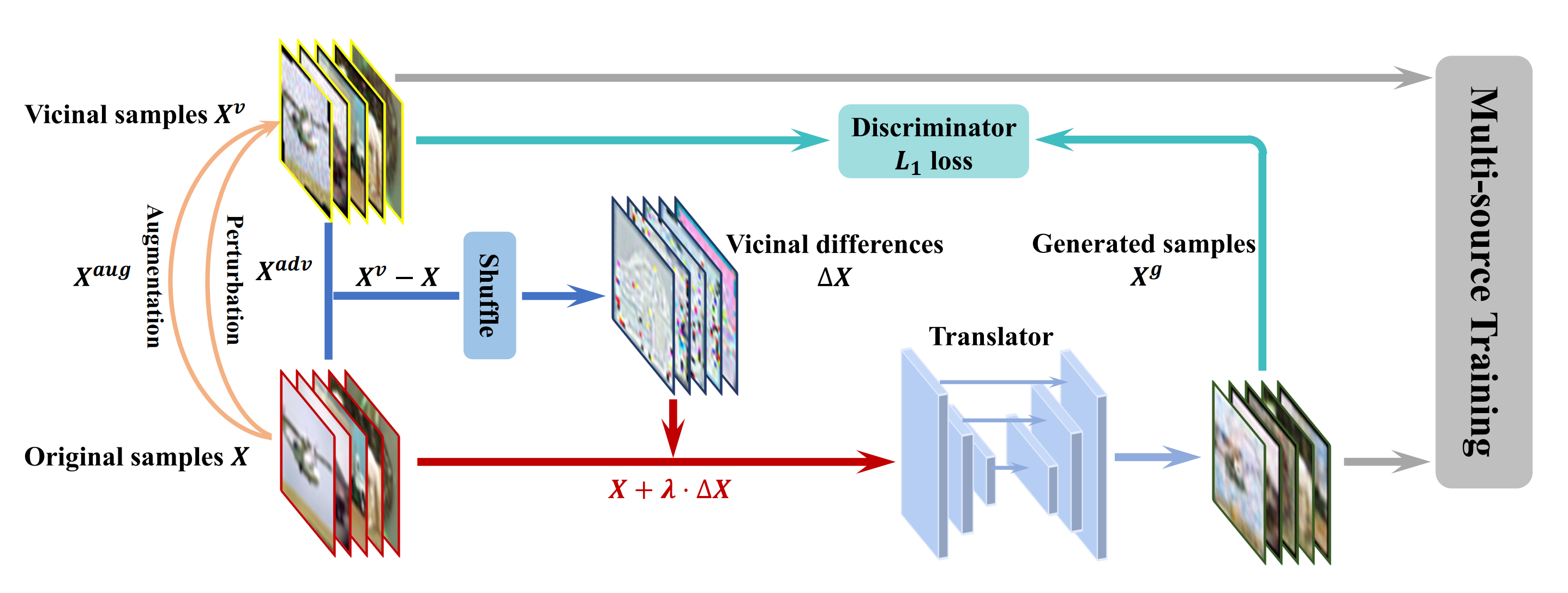
VITA: A Multi-Source Vicinal Transfer Augmentation Method for Out-of-Distribution Generalization
Invariance to diverse types of image corruption, such as noise, blurring, or colour shifts, is essential to establish robust models in computer vision. Data augmentation has been the major approach in improving the robustness against common corruptions. However, the samples produced by popular augmentation strategies deviate significantly from the underlying data manifold. As a result, performance is skewed toward certain types of corruption. To address this issue, we propose a multi-source vicinal transfer augmentation (VITA) method for generating diverse on-manifold samples. The proposed VITA consists of two complementary parts: tangent transfer and integration of multi-source vicinal samples. The tangent transfer creates initial augmented samples for improving corruption robustness. The integration employs a generative model to characterize the underlying manifold built by vicinal samples, facilitating the generation of on-manifold samples. Our proposed VITA significantly outperforms the current state-of-the-art augmentation methods, demonstrated in extensive experiments on corruption benchmarks.
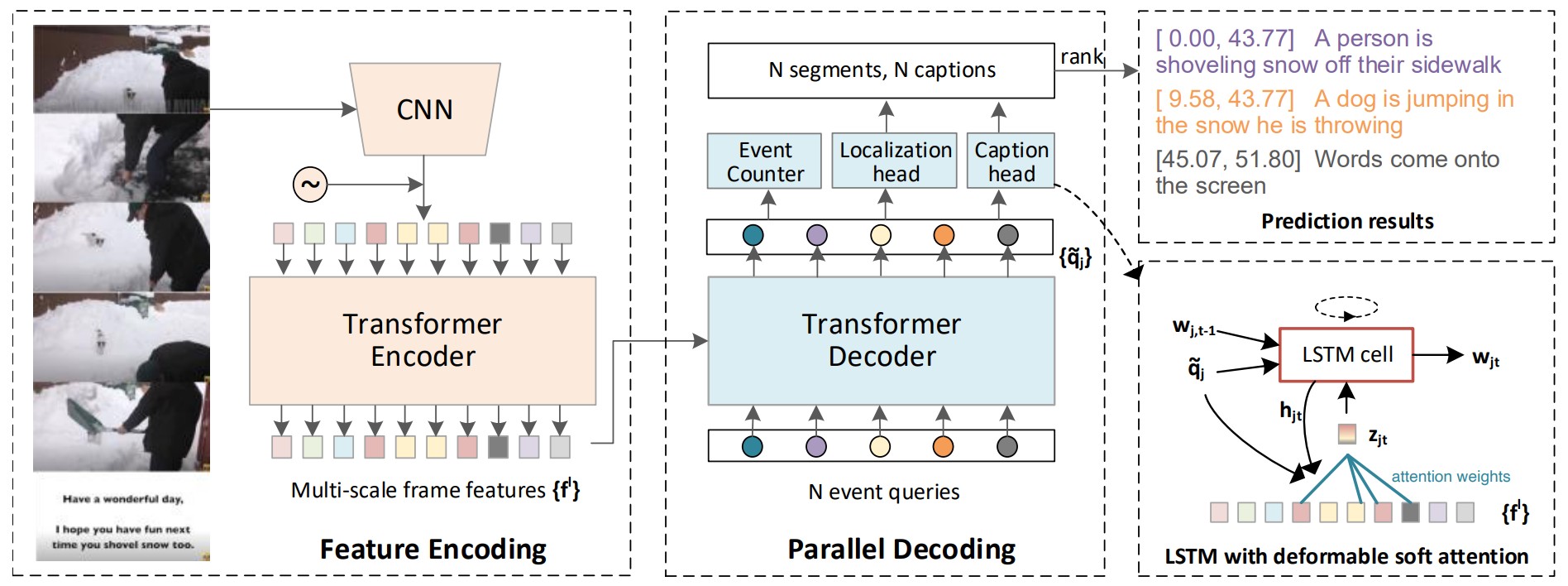
End-to-end Dense Video Captioning with Parallel Decoding
Dense video captioning aims to generate multiple associated captions with their temporal locations from the video. Previous methods follow a sophisticated “localize-then-describe” scheme, which heavily relies on numerous hand-crafted components. In this paper, we proposed a simple yet effective framework for end-to-end dense video captioning with parallel decoding (PDVC), by formulating the dense caption generation as a set prediction task. In practice, through stacking a newly proposed event counter on the top of a transformer decoder, the PDVC precisely segments the video into a number of event pieces under the holistic understanding of the video content, which effectively increases the coherence and readability of predicted captions. Compared with prior arts, the PDVC has several appealing advantages: (1) Without relying on heuristic non-maximum suppression or a recurrent event sequence selection network to remove redundancy, PDVC directly produces an event set with an appropriate size; (2) In contrast to adopting the two-stage scheme, we feed the enhanced representations of event queries into the localization head and caption head in parallel, making these two sub-tasks deeply interrelated and mutually promoted through the optimization; (3) Without bells and whistles, extensive experiments on ActivityNet Captions and YouCook2 show that PDVC is capable of producing high-quality captioning results, surpassing the state-of-the-art two-stage methods when its localization accuracy is on par with them.

Show, Tell and Rephrase: Diverse Video Captioning via Two-Stage Progressive Training
Describing a video using natural language is an inherently one-to-many translation task. To generate diverse captions, existing VAE-based generative models typically learn factorized latent codes via one-stage training merely from stand-alone video-caption pairs. However, such a paradigm neglects set-level relationships among captions from the same video, not fully capturing the underlying multimodality of the generative process. To overcome this shortcoming, we leverage neighboring descriptions for the same video that are articulated with noticeable topics and language variations (i.e., paraphrases). To this end, we propose a novel progressive training method by decomposing the learning of latent variables into two stages that are topic-oriented and paraphrase-oriented, respectively. Specifically, the model learns from divergent topic sentences obtained by semantic-based clustering in the first stage. It is then trained again through paraphrases with a cluster-aware adaptive regularization, allowing more intra-cluster variations. Furthermore, we introduce an overall metric DAUM, a Diversity- Accuracy Unified Metric to consider both the precision of the generated caption set and its coverage on the reference set, which has proved to have a higher correlation with human judgment than previous precision-only metrics. Extensive experiments on three large-scale video datasets show that the proposed training strategy can achieve superior performance in terms of accuracy, diversity, and DAUM over several baselines.
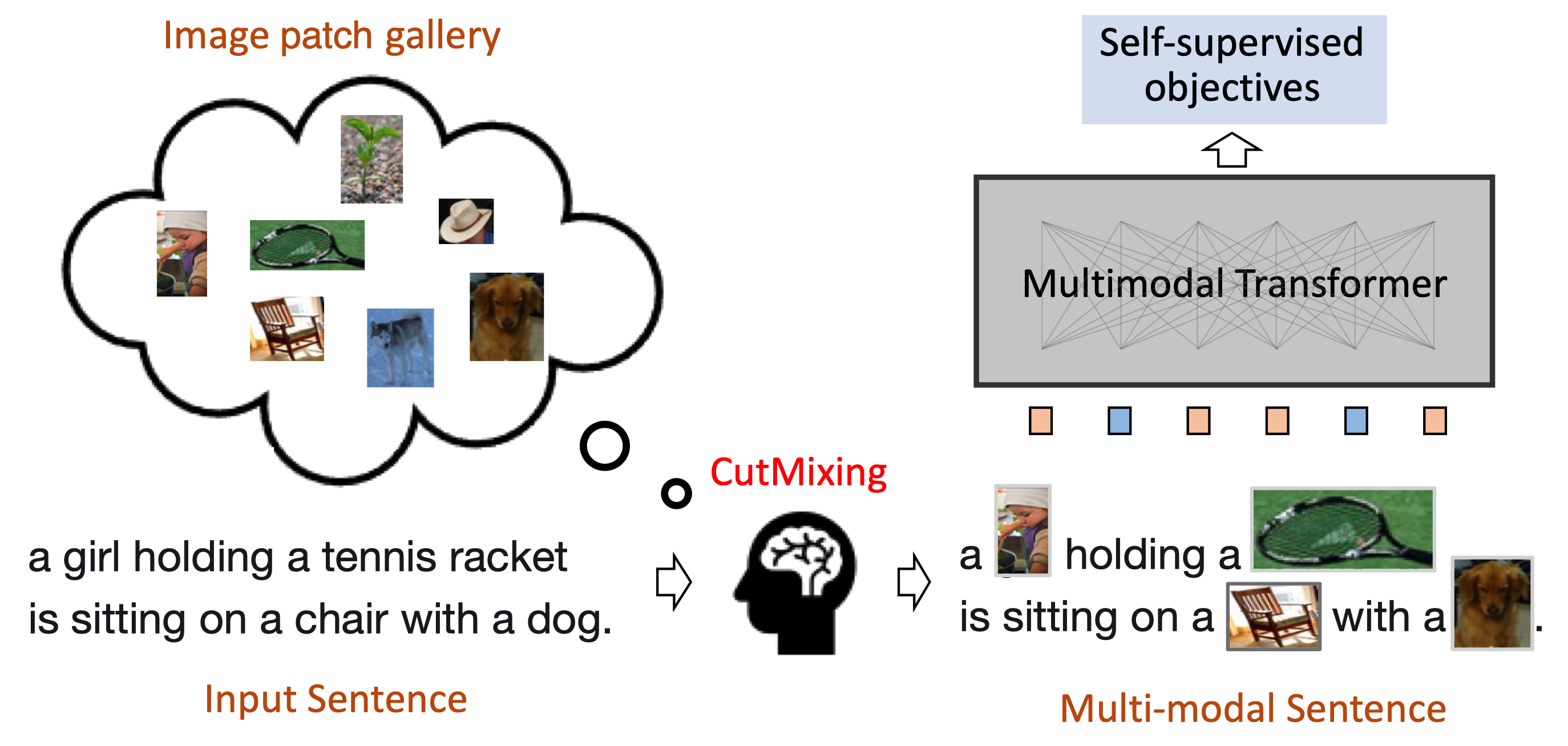
VLMixer: Unpaired Vision-Language Pre-training via Cross-Modal CutMix
Existing vision-language pre-training (VLP) methods primarily rely on paired image-text datasets, which are either annotated by enormous human labors, or crawled from the internet followed by elaborate data cleaning techniques. To reduce the dependency on well-aligned imagetext pairs, it is promising to directly leverage the large-scale text-only and image-only corpora. This paper proposes a data augmentation method, namely cross-modal CutMix (CMC), for implicit cross-modal alignment learning in unpaired VLP. Specifically, CMC transforms natural sentences from the textual view into a multi-modal view, where visually-grounded words in a sentence are randomly replaced by diverse image patches with similar semantics. There are several appealing proprieties of the proposed CMC. First, it enhances the data diversity while keeping the semantic meaning intact for tackling problems where the aligned data are scarce; Second, by attaching cross-modal noise on uni-modal data, it guides models to learn token-level interactions across modalities for better denoising. Furthermore, we present a new unpaired VLP method, dubbed as VLMixer, that integrates CMC with contrastive learning to pull together the uni-modal and multi-modal views for better instance-level alignments among different modalities. Extensive experiments on five downstream tasks show that VLMixer could surpass previous state-of-the-art unpaired VLP methods.
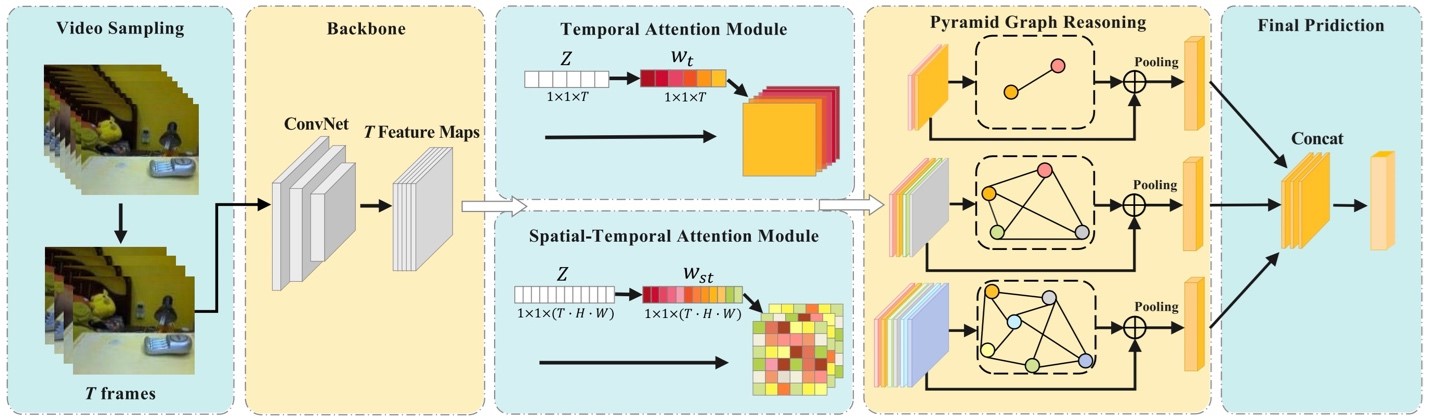
Spatial-Temporal Pyramid Graph Reasoning for Action Recognition
Spatial-temporal relation reasoning is a significant yet challenging problem for video action recognition. Previous works typically apply local operations like 2D or 3D CNNs to conduct space-time interactions in video sequences, or simply capture space-time long-range relations of a single fixed scale. However, this is inadequate for obtaining a comprehensive action representation. Besides, most models treat all input frames equally for the final classification, without selecting key frames and motion-sensitive regions. This introduces irrelevant video content and hurts the performance of models. In this paper, we propose a generic Spatial-Temporal Pyramid Graph Network (STPG-Net) to adaptively capture long-range spatial-temporal relations in video sequences at multiple scales. Specifically, we design a temporal attention (TA) module and a spatial-temporal attention (STA) module to learn the contribution of each frame and each space-time region to an action at a feature level, respectively. We then apply the selected key information to build spatial-temporal pyramid graphs for long-range relation reasoning and more comprehensive action representation learning. STPG-Net can be flexibly integrated into 2D and 3D backbone networks in a plug-and-play manner. Extensive experiments show that it brings consistent improvements over many challenging baselines on several standard action recognition benchmarks ( i.e. , Something-Something V1 & V2, and FineGym), demonstrating the effectiveness of our approach.
Learning Dual-Fused Modality-Aware Representations for RGBD Tracking
With the development of depth sensors in recent years, RGBD object tracking has received significant attention. Compared with the traditional RGB object tracking, the addition of the depth modality can effectively solve the target and background interference. However, some existing RGBD trackers use the two modalities separately and thus some particularly useful shared information between them is ignored. On the other hand, some methods attempt to fuse the two modalities by treating them equally, resulting in the missing of modality-specific features. To tackle these limitations, we propose a novel Dual-fused Modality-aware Tracker (termed DMTracker) which aims to learn informative and discriminative representations of the target objects for robust RGBD tracking. The first fusion module focuses on extracting the shared information between modalities based on cross-modal attention. The second aims at integrating the RGB-specific and depth-specific information to enhance the fused features. By fusing both the modality-shared and modality-specific information in a modality-aware scheme, our DMTracker can learn discriminative representations in complex tracking scenes. Experiments show that our proposed tracker achieves very promising results on challenging RGBD benchmarks.

Deep learning for video object segmentation: a review
In this paper, we present a systematic review of the deep learning-based video segmentation literature, highlighting the pros and cons of each category of approaches. Concretely, we start by introducing the definition, background concepts and basic ideas of algorithms in this field. Subsequently, we summarise the datasets for training and testing a video object segmentation algorithm, as well as common challenges and evaluation metrics. Next, previous works are grouped and reviewed based on how they extract and use spatial and temporal features, where their architectures, contributions and the differences among each other are elaborated. At last, the quantitative and qualitative results of several representative methods on a dataset with many remaining challenges are provided and analysed, followed by further discussions on future research directions. This article is expected to serve as a tutorial and source of reference for learners intended to quickly grasp the current progress in this research area and practitioners interested in applying the video object segmentation methods to their problems.

Video object segmentation using point-based memory network
Recent years have witnessed the prevalence of memory-based methods for Semi-supervised Video Object Segmentation (SVOS) which utilise past frames efficiently for label propagation. When conducting feature matching, fine-grained multi-scale feature matching has typically been performed using all query points, which inevitably results in redundant computations and thus makes the fusion of multi-scale results ineffective. In this paper, we develop a new Point-based Memory Network, termed as PMNet, to perform fine-grained feature matching on hard samples only, assuming that easy samples can already obtain satisfactory matching results without the need for complicated multi-scale feature matching. Our approach first generates an uncertainty map from the initial decoding outputs. Next, the fine-grained features at uncertain locations are sampled to match the memory features on the same scale. Finally, the matching results are further decoded to provide a refined output. The point-based scheme works with the coarsest feature matching in a complementary and efficient manner. Furthermore, we propose an approach to adaptively perform global or regional matching based on the motion history of memory points, making our method more robust against ambiguous backgrounds. Experimental results on several benchmark datasets demonstrate the superiority of our proposed method over state-of-the-art methods.
Fast Vehicle Identification via Ranked Semantic Sampling Based Embedding
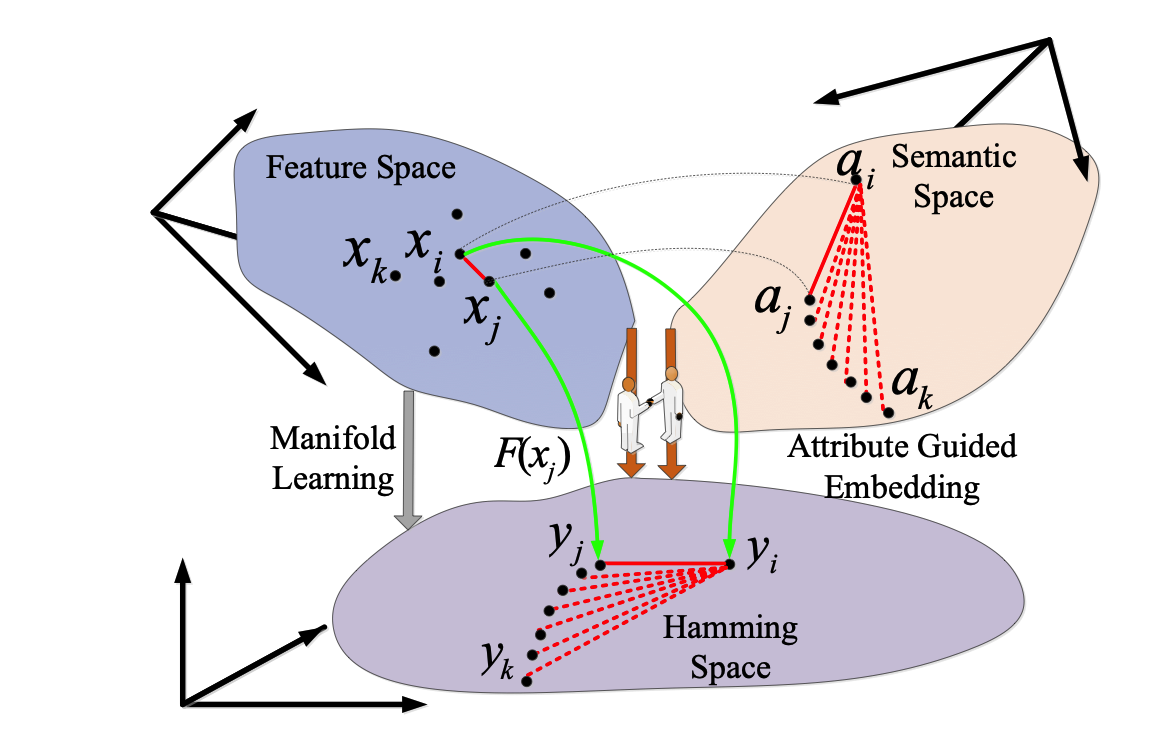
Identifying vehicles across cameras in traffic surveillance is fundamentally important for public safety purposes. However, despite some preliminary work, the rapid vehicle search in large-scale datasets has not been investigated. Moreover, modelling a view-invariant similarity between vehicle images from different views is still highly challenging. To address the problems, in this paper, we propose a Ranked Semantic Sampling (RSS) guided binary embedding method for fast crossview vehicle Re-IDentification (Re-ID). The search can be conducted by efficiently computing similarities in the projected space. Unlike previous methods using random sampling, we design tree-structured attributes to guide the mini-batch sampling. The ranked pairs of hard samples in the mini-batch can improve the convergence of optimization. By minimizing a novel ranked semantic distance loss defined according to the structure, the learned Hamming distance is view-invariant, which enables cross-view Re-ID. The experimental results demonstrate that RSS outperforms the state-of-the-art approaches and the learned embedding from one dataset can be transferred to achieve the task of vehicle Re-ID on another dataset.
FREE: Feature Refinement for Generalized Zero-Shot Learning
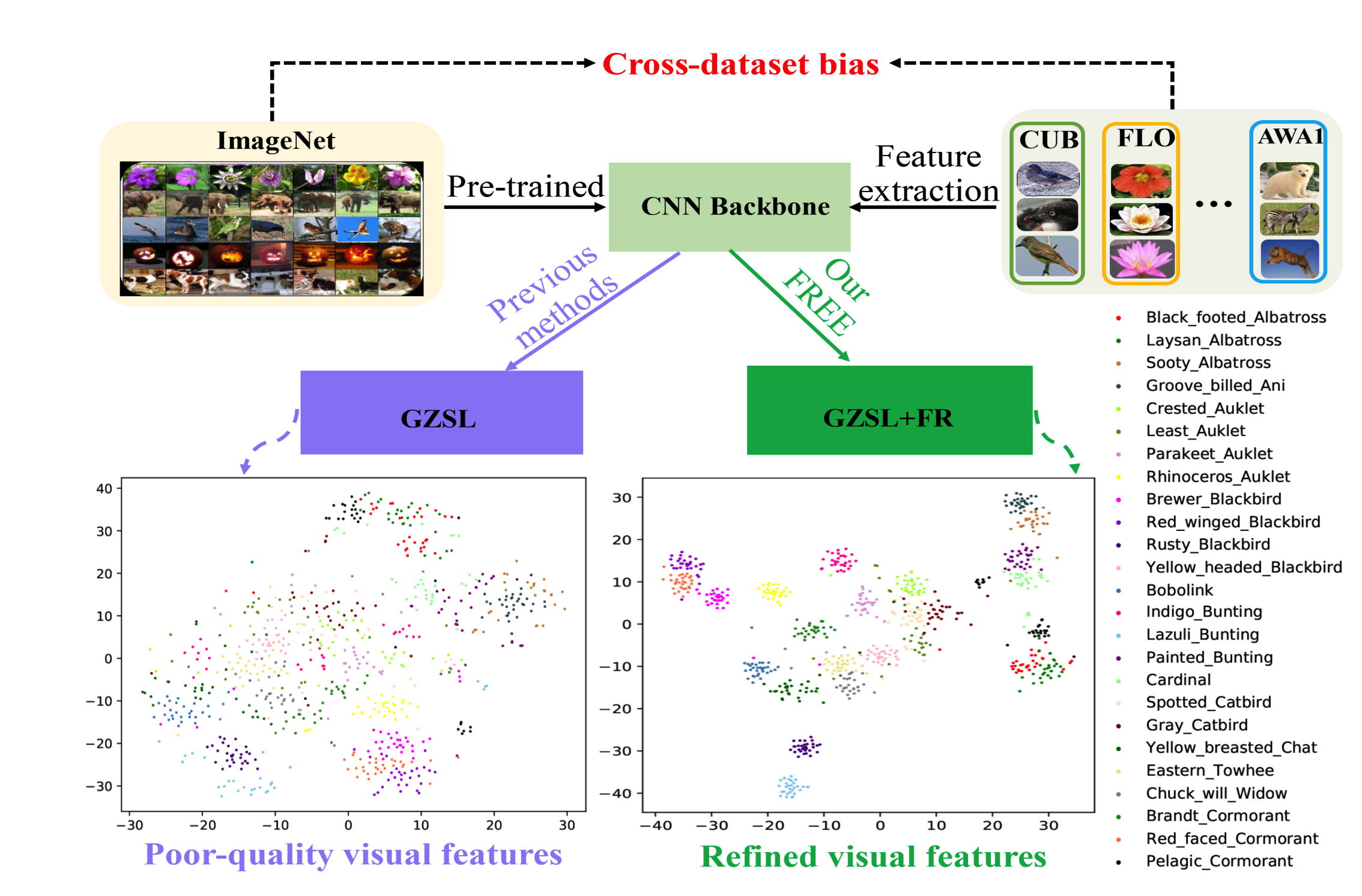
Generalized zero-shot learning (GZSL) has achieved significant progress, with many efforts dedicated to overcoming the problems of visual-semantic domain gap and seen-unseen bias. However, most existing methods directly use feature extraction models trained on ImageNet alone, ignoring the cross-dataset bias between ImageNet and GZSL benchmarks. Such a bias inevitably results in poor-quality visual features for GZSL tasks, which potentially limits the recognition performance on both seen and unseen classes. In this paper, we propose a simple yet effective GZSL method, termed feature refinement for generalized zero-shot learning (FREE), to tackle the above problem. FREE employs a feature refinement (FR) module that incorporates semantic→visual mapping into a unified generative model to refine the visual features of seen and unseen class samples. Furthermore, we propose a self-adaptive margin center loss (SAMC-loss) that cooperates with a semantic cycle-consistency loss to guide FR to learn class- and semantically-relevant representations, and concatenate the features in FR to extract the fully refined features. Extensive experiments on five benchmark datasets demonstrate the significant performance gain of FREE over its baseline and current state-of-the-art methods.
Hetero-manifold Regularization for Cross-modal Hashing
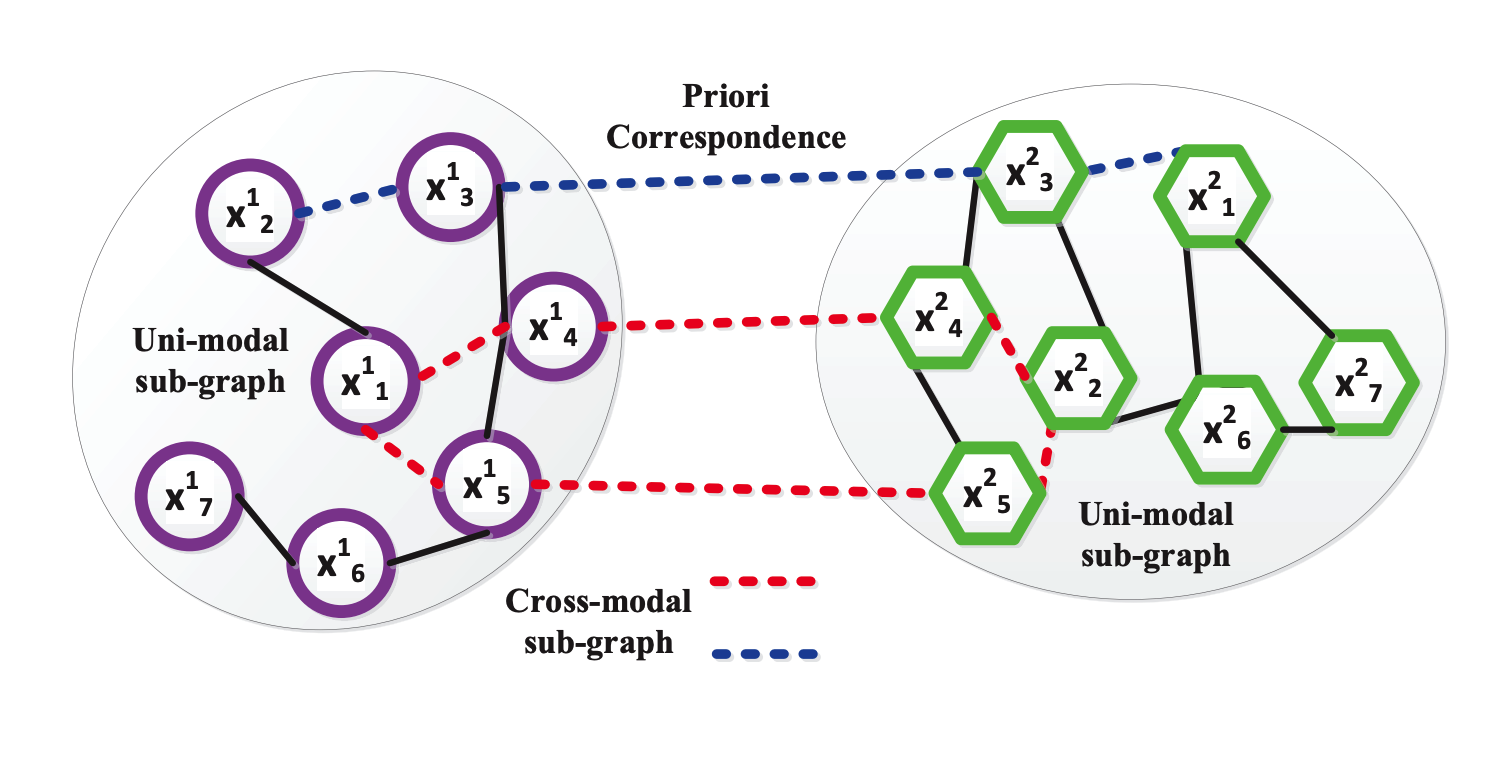
Recently, cross-modal search has attracted considerable attention but remains a very challenging task because of the integration complexity and heterogeneity of the multi-modal data. To address both challenges, in this paper, we propose a novel method termed hetero-manifold regularisation (HMR) to supervise the learning of hash functions for efficient cross-modal search. A hetero-manifold integrates multiple sub-manifolds defined by homogeneous data with the help of cross-modal supervision information. Taking advantages of the hetero-manifold, the similarity between each pair of heterogeneous data could be naturally measured by three order random walks on this hetero-manifold. Furthermore, a novel cumulative distance inequality defined on the hetero-manifold is introduced to avoid the computational difficulty induced by the discreteness of hash codes. By using the inequality, cross-modal hashing is transformed into a problem of hetero-manifold regularised support vector learning. Therefore, the performance of cross-modal search can be significantly improved by seamlessly combining the integrated information of the hetero-manifold and the strong generalisation of the support vector machine. Comprehensive experiments show that the proposed HMR achieve advantageous results over the state-of-the-art methods in several challenging cross-modal tasks.
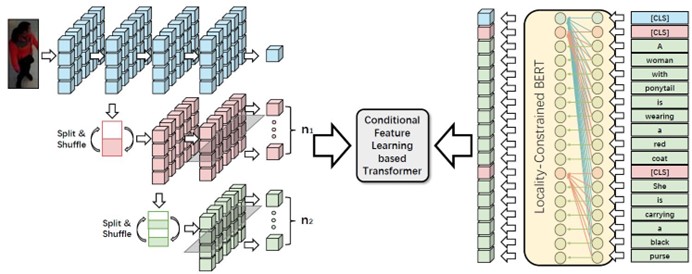
Conditional Feature Learning Based Transformer for Text-Based Person Search
Text-based person search aims at retrieving the target person in an image gallery using a descriptive sentence of that person. The core of this task is to calculate a similarity score between the pedestrian image and description, which requires inferring the complex latent correspondence between image sub-regions and textual phrases at different scales. Transformer is an intuitive way to model the complex alignment by its self-attention mechanism. Most previous Transformer-based methods simply concatenate image region features and text features as input and learn a cross-modal representation in a brute force manner. Such weakly supervised learning approaches fail to explicitly build alignment between image region features and text features, causing an inferior feature distribution. In this paper, we present CFLT, Conditional Feature Learning based Transformer. It maps the sub-regions and phrases into a unified latent space and explicitly aligns them by constructing conditional embeddings where the feature of data from one modality is dynamically adjusted based on the data from the other modality. The output of our CFLT is a set of similarity scores for each sub-region or phrase rather than a cross-modal representation. Furthermore, we propose a simple and effective multi-modal re-ranking method named Re-ranking scheme by Visual Conditional Feature (RVCF). Benefit from the visual conditional feature and better feature distribution in our CFLT, the proposed RVCF achieves significant performance improvement. Experimental results show that our CFLT outperforms the state-of-the-art methods by 7.03% in terms of top-1 accuracy and 5.01% in terms of top-5 accuracy on the text-based person search dataset.
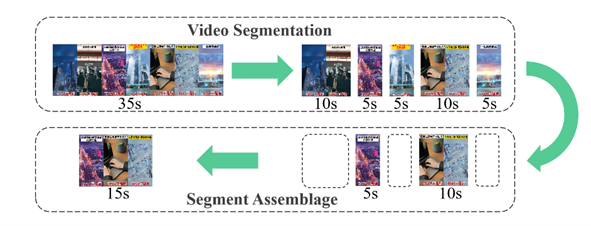
Multi-modal Segment Assemblage Network for Ad Video Editing with Importance-Coherence Reward
Advertisement video editing aims to automatically edit advertising videos into shorter videos while retaining coherent content and crucial information conveyed by advertisers. It mainly contains two stages: video segmentation and segment assemblage. The existing method performs well at video segmentation stages but suffers from the problems of dependencies on extra cumbersome models and poor performance at the segment assemblage stage. To address these problems, we propose M-SAN (Multi-modal Segment Assemblage Network) which can perform efficient and coherent segment assemblage task end-to-end. It utilizes multi-modal representation extracted from the segments and follows the Encoder-Decoder Ptr-Net framework with the Attention mechanism. Importance-coherence reward is designed for training M-SAN. We experiment on the Ads-1k dataset with 1000+ videos under rich ad scenarios collected from advertisers. To evaluate the methods, we propose a unified metric, Imp-Coh@Time, which comprehensively assesses the importance, coherence, and duration of the outputs at the same time. Experimental results show that our method achieves better performance than random selection and the previous method on the metric. Ablation experiments further verify that multi-modal representation and importance-coherence reward significantly improve the performance. Ads-1k dataset is available at: https://github.com/yunlong10/Ads-1k.
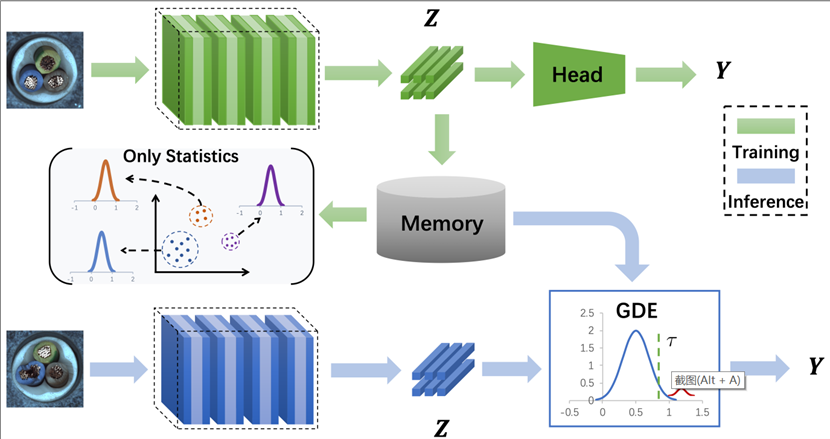
Towards Continual Adaptation in Industrial Anomaly Detection
Anomaly detection (AD) has gained widespread attention due to its ability to identify defects in industrial scenarios using only normal samples. Although traditional AD methods achieved acceptable performance, they mainly focus on the current set of examples solely, leading to catastrophic forgetting of previously learned tasks when trained on a new one. Due to the limitation of flexibility and the requirements of realistic industrial scenarios, it is urgent to enhance the ability of continual adaptation of AD models. There- fore, this paper proposes a unified framework by incorporating continual learning (CL) to achieve our newly designed task of con- tinual anomaly detection (CAD). Note that, we observe that data augmentation strategy can make AD methods well adapted to su- pervised CL (SCL) via constructing anomaly samples. Based on this, we hence propose a novel method named Distribution of Nor- mal Embeddings (DNE), which utilizes the feature distribution of normal training samples from past tasks. It not only effectively alleviates catastrophic forgetting in CAD but also can be integrated with SCL methods to further improve their performance. Extensive experiments and visualization results on the popular benchmark dataset MVTec AD, have demonstrated advanced performance and the excellent continual adaption ability of our proposed method compared to other AD methods. To the best of our knowledge, we are the first to introduce and tackle the task of CAD. We believe that the proposed task and benchmark will be beneficial to the field of AD.
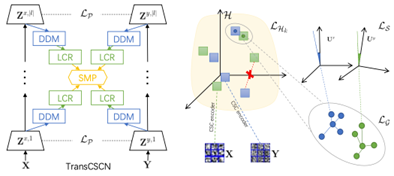
Generalized Brain Image Synthesis with Transferable Convolutional Sparse Coding Networks
High inter-equipment variability and expensive examination costs of brain imaging remain key challenges in leveraging the heterogeneous scans effectively. Despite rapid growth in image-to-image translation with deep learning models, the target brain data may not always be achievable due to the specific attributes of brain imaging. In this paper, we present a novel generalized brain image synthesis method, powered by our transferable convolutional sparse coding networks, to address the lack of interpretable cross-modal medical image representation learning. The proposed approach masters the ability to imitate the machine-like anatomically meaningful imaging by translating features directly under a series of mathematical processings, leading to the reduced domain discrepancy while enhancing model transferability. Specifically, we first embed the globally normalized features into a domain discrepancy metric to learn the domain-invariant representations, then optimally preserve domain-specific geometrical property to reflect the intrinsic graph structures, and further penalize their subspace mismatching to reduce the generalization error. The overall framework is cast in a minimax setting, and the extensive experiments show that the proposed method yields state-of-the-art results on multiple dataset.
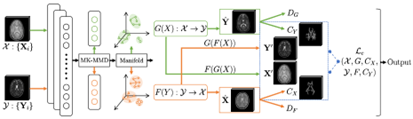
MCMT-GAN: Multi-Task Coherent Modality Transferable GAN for 3D Brain Image Synthesis. IEEE Transactions on Image Processing
The ability to synthesize multi-modality data is highly desirable for many computer-aided medical applications, e.g. clinical diagnosis and neuroscience research, since rich imaging cohorts offer diverse and complementary information unraveling human tissues. However, collecting acquisitions can be limited by adversary factors such as patient discomfort, expensive cost and scanner unavailability. In this paper, we propose a multi-task coherent modality transferable GAN (MCMT-GAN) to address this issue for brain MRI synthesis in an unsupervised manner. Through combining the bidirectional adversarial loss, cycle-consistency loss, domain adapted loss and manifold regularization in a volumetric space, MCMT-GAN is robust for multi-modality brain image synthesis with visually high fidelity. In addition, we complement discriminators collaboratively working with segmentors which ensure the usefulness of our results to segmentation task. Experiments evaluated on various cross-modality synthesis show that our method produces visually impressive results with substitutability for clinical post-processing and also exceeds the state-of-the-art methods.

Seminar Learning for Click-Level Weakly Supervised Semantic Segmentation
Annotation burden has become one of the biggest barriers to semantic segmentation. Approaches based on click-level annotations have therefore attracted increasing attention due to their superior trade-off between supervision and annotation cost. In this paper, we propose seminar learning, a new learning paradigm for semantic segmentation with click-level supervision. The fundamental rationale of seminar learning is to leverage the knowledge from different networks to compensate for insufficient information provided in click-level annotations. Mimicking a seminar, our seminar learning involves a teacher-student and a studentstudent module, where a student can learn from both skillful teachers and other students. The teacher-student module uses a teacher network based on the exponential moving average to guide the training of the student network. In the student-student module, heterogeneous pseudo-labels are proposed to bridge the transfer of knowledge among students to enhance each other’s performance. Experimental results demonstrate the effectiveness of seminar learning, which achieves the new state-of-the-art performance of 72.51% (mIOU), surpassing previous methods by a large margin of up to 16.88% on the Pascal VOC 2012 dataset.
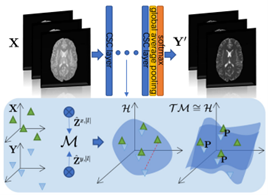
Brain Image Synthesis with Unsupervised Multivariate Canonical CSCellNet
Recent advances in neuroscience have highlighted the effectiveness of multi-modal medical data for investigating certain pathologies and understanding human cognition. However, obtaining full sets of different modalities is limited by various factors, such as long acquisition times, high examination costs and artifact suppression. In addition, the complexity, high dimensionality and heterogeneity of neuroimaging data remains another key challenge in leveraging existing randomized scans effectively, as data of the same modality is often measured differently by different machines. There is a clear need to go beyond the traditional imaging-dependent process and synthesize anatomically specific target-modality data from a source input. In this paper, we propose to learn dedicated features that cross both intre- and intra-modal variations using a novel CSCℓ4Net. Through an initial unification of intramodal data in the feature maps and multivariate canonical adaptation, CSCℓ4Net facilitates feature-level mutual transformation. The positive definite Riemannian manifoldpenalized data fidelity term further enables CSCℓ4Net to reconstruct missing measurements according to transformed features. Finally, the maximization ℓ4-norm boils down to a computationally efficient optimization problem. Extensive experiments validate the ability and robustness of our CSCℓ4Net compared to the state-of-the-art methods on multiple datasets.
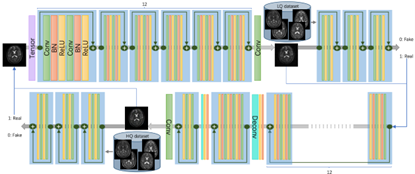
Super-Resolution and Inpainting with Degraded and Upgraded Generative Adversarial Networks
Image super-resolution (SR) and image inpainting are two topical problems in medical image processing. Existing methods for solving the problems are either tailored to recovering a high-resolution version of the low-resolution image or focus on filling missing values, thus inevitably giving rise to poor performance when the acquisitions suffer from multiple degradations. In this paper, we explore the possibility of super-resolving and inpainting images to handle multiple degradations and therefore improve their usability. We construct a unified and scalable framework to overcome the drawbacks of propagated errors caused by independent learning. We additionally provide improvements over previously proposed super-resolution approaches by modeling image degradation directly from data observations rather than bicubic downsampling. To this end, we propose HLH-GAN, which includes a high-to-low (H-L) GAN together with a low-to-high (L-H) GAN in a cyclic pipeline for solving the medical image degradation problem. Our comparative evaluation demonstrates that the effectiveness of the proposed method on different brain MRI datasets. In addition, our method outperforms many existing super-resolution and inpainting approaches.
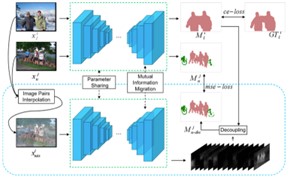
GuidedMix-Net: Semi-supervised Semantic Segmentation by Using Labeled Images as Reference
Semi-supervised learning is a challenging problem which aims to construct a model by learning from limited labeled examples. Numerous methods for this task focus on utilizing the predictions of unlabeled instances consistency alone to regularize networks. However, treating labeled and unlabeled data separately often leads to the discarding of mass prior knowledge learned from the labeled examples. In this paper, we propose a novel method for semi-supervised semantic segmentation named GuidedMix-Net, by leveraging labeled information to guide the learning of unlabeled instances. Specifically, GuidedMix-Net employs three operations: 1) interpolation of similar labeled-unlabeled image pairs; 2) transfer of mutual information; 3) generalization of pseudo masks. It enables segmentation models can learning the higher-quality pseudo masks of unlabeled data by transfer the knowledge from labeled samples to unlabeled data. Along with supervised learning for labeled data, the prediction of unlabeled data is jointly learned with the generated pseudo masks from the mixed data. Extensive experiments on PASCAL VOC 2012, and Cityscapes demonstrate the effectiveness of our GuidedMix-Net, which achieves competitive segmentation accuracy and significantly improves the mIoU over 7% compared to previous approaches.
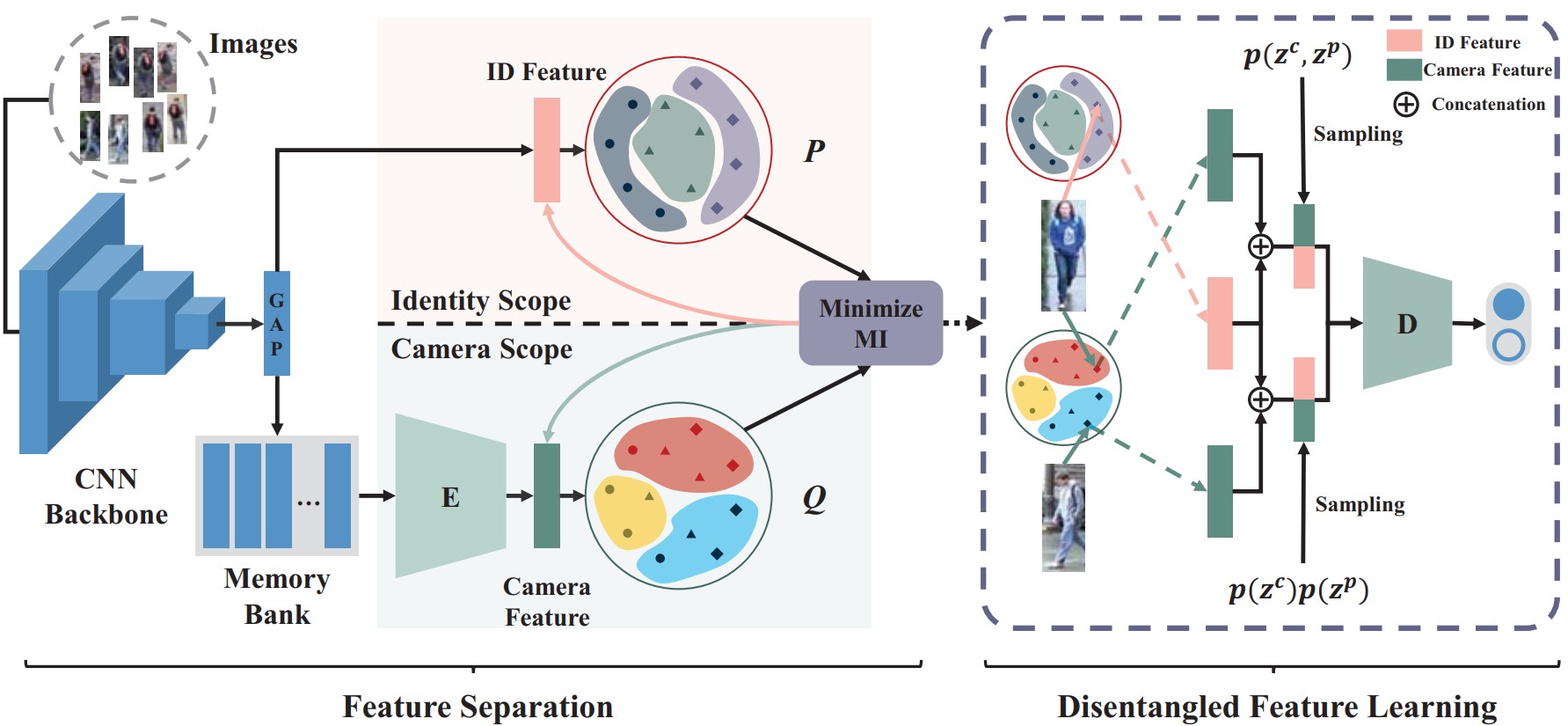
Camera-Agnostic Person Re-Identification via Adversarial Disentangling Learning
Despite the success of single-domain person re-identification (ReID), current supervised models degrade dramatically when deployed to unseen domains, mainly due to the discrepancy across cameras. To tackle this issue, we propose an Adversarial Disentangling Learning (ADL) framework to decouple camera-related and ID-related features, which can be readily used for camera-agnostic person ReID. ADL adopts a discriminative way instead of the mainstream generative styles in disentangling methods, eg., GAN or VAE based, because for person ReID task only the information to discriminate IDs is needed, and more information to generate images are redundant and may be noisy. Specifically, our model involves a feature separation module that encodes images into two separate feature spaces and a disentangled feature learning module that performs adversarial training to minimize mutual information. We design an effective solution to approximate and minimize mutual information by transforming it into a discrimination problem. The two modules are co-designed to obtain strong generalization ability by only using source dataset. Extensive experiments on three public benchmarks show that our method outperforms the state-of-the-art generalizable person ReID model by a large margin.
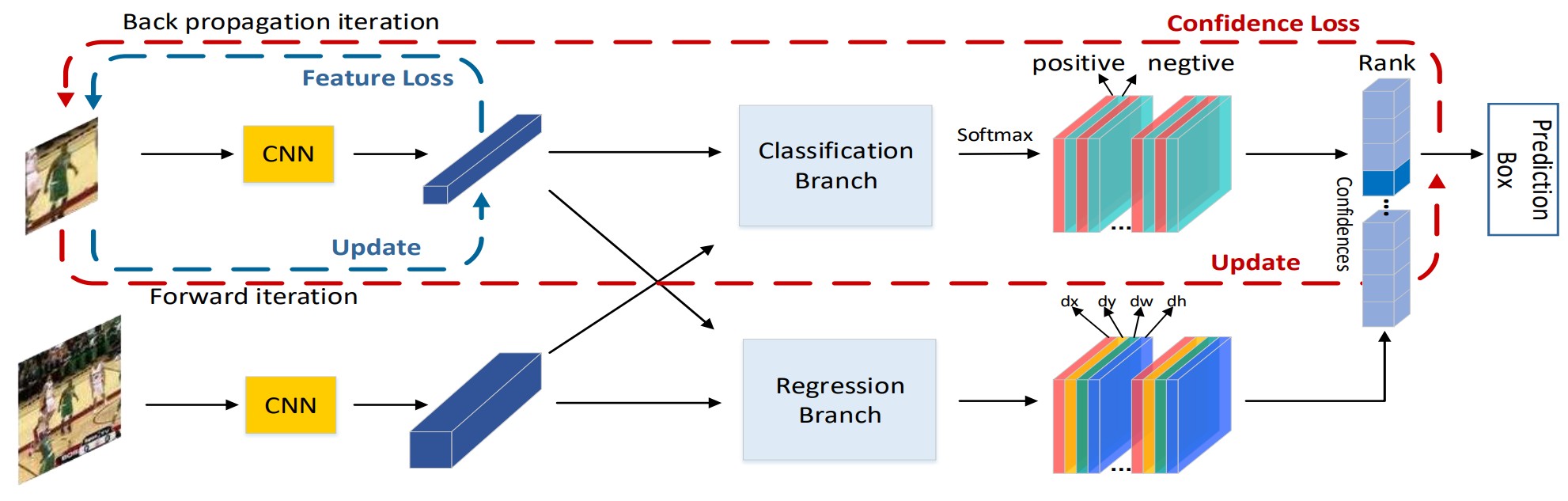
One-shot Adversarial Attacks on Visual Tracking with Dual Attention
Almost all adversarial attacks in computer vision are aimed at pre-known object categories, which could be offline trained for generating perturbations. But as for visual object tracking, the tracked target categories are normally unknown in advance. However, the tracking algorithms also have potential risks of being attacked, which could be maliciously used to fool the surveillance systems. Meanwhile, it is still a challenging task that adversarial attacks on tracking since it has the free-model tracked target. Therefore, to help draw more attention to the potential risks, we study adversarial attacks on tracking algorithms. In this paper, we propose a novel one-shot adversarial attack method to generate adversarial examples for free-model single object tracking, where merely adding slight perturbations on the target patch in the initial frame causes state-of-the-art trackers to lose the target in subsequent frames. Specifically, the optimization objective of the proposed attack consists of two components and leverages the dual attention mechanisms. The first component adopts a targeted attack strategy by optimizing the batch confidence loss with confidence attention while the second one applies a general perturbation strategy by optimizing the feature loss with channel attention. Experimental results show that our approach can significantly lower the accuracy of the most advanced Siamese network-based trackers on three benchmarks.
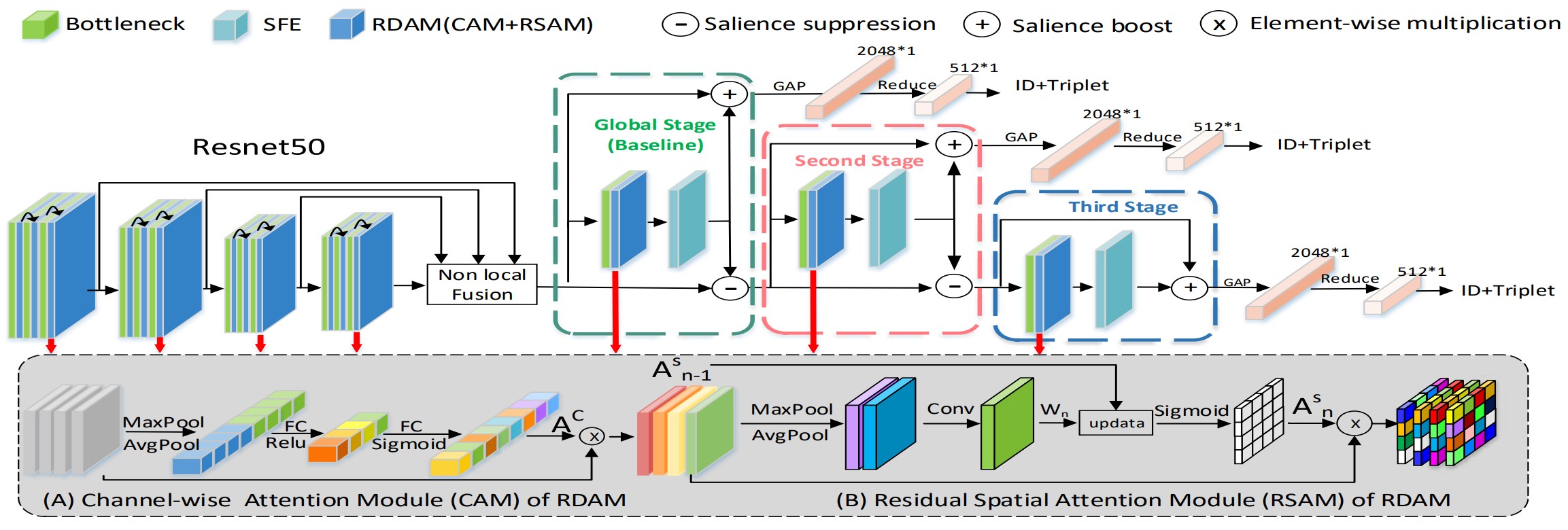
Salience-Guided Cascaded Suppression Network for Person Re-Identification
Employing attention mechanisms to model both global and local features as a final pedestrian representation has become a trend for person re-identification (Re-ID) algorithms. A potential limitation of these methods is that they focus on the most salient features, but the re-identification of a person may rely on diverse clues masked by the most salient features in different situations, e.g., body, clothes or even shoes. To handle this limitation, we propose a novel Salience-guided Cascaded Suppression Network (SCSN) which enables the model to mine diverse salient features and integrate these features into the final representation by a cascaded manner. Our work makes the following contributions: (i) We observe that the previously learned salient features may hinder the network from learning other important information. To tackle this limitation, we introduce a cascaded suppression strategy, which enables the network to mine diverse potential useful features that be masked by the other salient features stage-by-stage and each stage integrates different feature embedding for the last discriminative pedestrian representation. (ii) We propose a Salient Feature Extraction (SFE) unit, which can suppress the salient features learned in the previous cascaded stage and then adaptively extracts other potential salient feature to obtain different clues of pedestrians. (iii) We develop an efficient feature aggregation strategy that fully increases the network’s capacity for all potential salience features. Finally, experimental results demonstrate that our proposed method outperforms the state-of-the-art methods on four large-scale datasets. Especially, our approach exceeds the current best method by over 7% on the CUHK03 dataset.
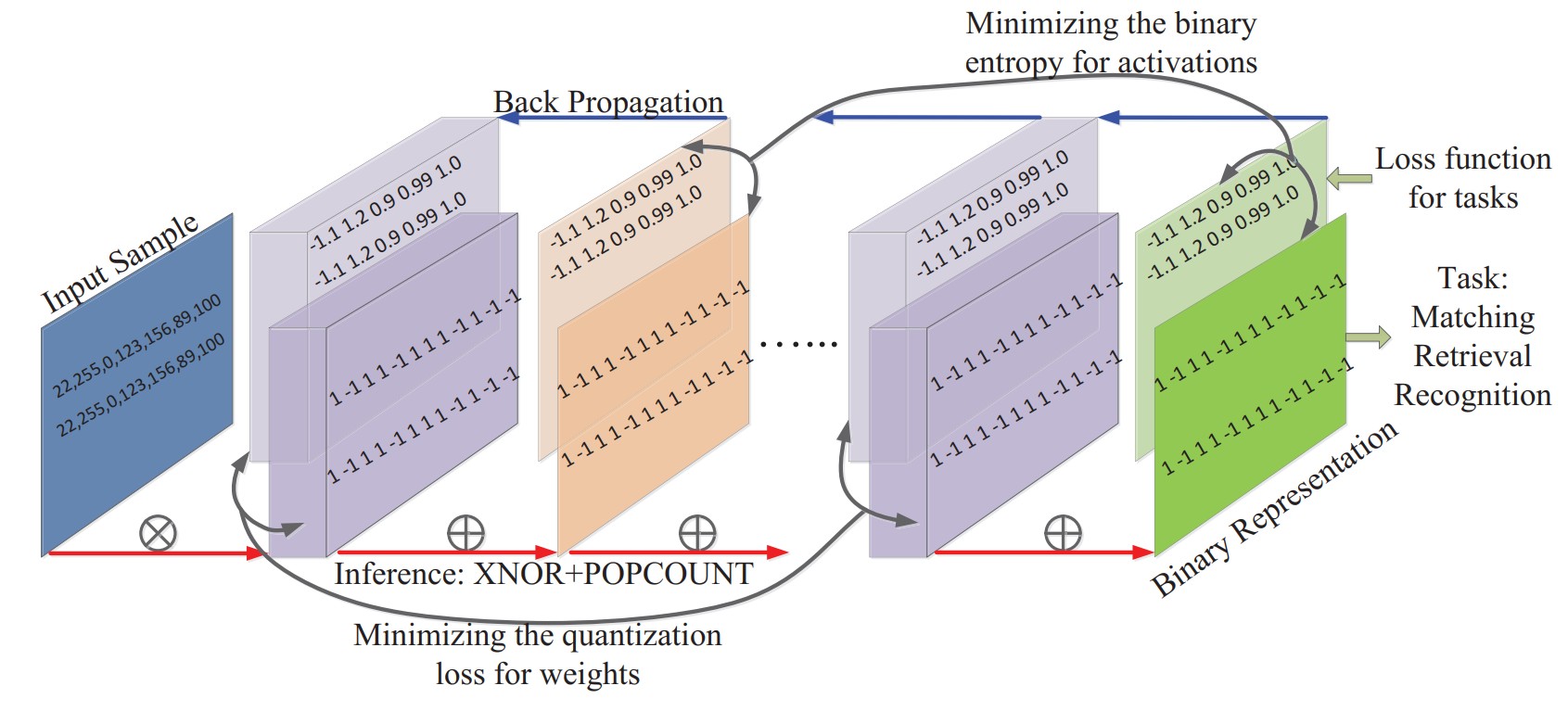
Binarized Neural Networks for Resource-Efficient Hashing with Minimizing Quantization Loss
In order to solve the problem of memory consumption and computational requirements, this paper proposes a novel learning binary neural network framework to achieve a resource-efficient deep hashing. In contrast to floating-point (32-bit) full-precision networks, the proposed method achieves a 32x model compression rate. At the same time, computational burden in convolution is greatly reduced due to efficient Boolean operations. To this end, in our framework, a new quantization loss defined between the binary weights and the learned real values is minimized to reduce the model distortion, while, by minimizing a binary entropy function, the discrete optimization is successfully avoided and the stochastic gradient descend method can be used smoothly. More importantly, we provide two theories to demonstrate the necessity and effectiveness of minimizing the quantization losses for both weights and activations. Numerous experiments show that the proposed method can achieve fast code generation without sacrificing accuracy.
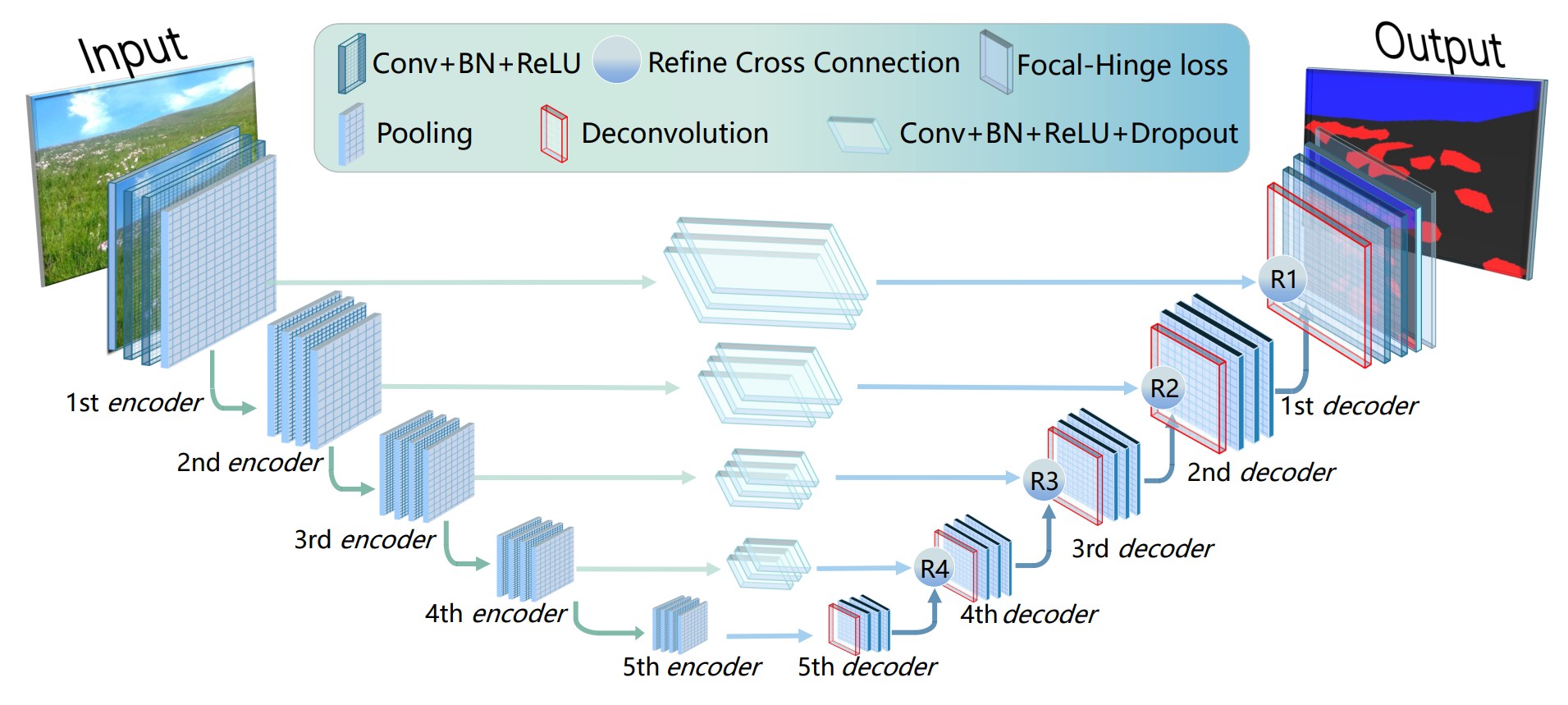
Automatic Grassland Degradation Estimation Using Deep Learning
Grassland degradation estimation is essential to prevent global land desertification and sandstorms. Typically, the key to such estimation is to measure the coverage of indicator plants. However, traditional methods of estimation rely heavily on human eyes and manual labor, thus inevitably leading to subjective results and high labor costs. In contrast, deep learning-based image segmentation algorithms are potentially capable of automatic assessment of the coverage of indicator plants. Nevertheless, a suitable image dataset comprising grassland images is not publicly available. To this end, we build an original Automatic Grassland Degradation Estimation Dataset (AGDE-Dataset), with a large number of grassland images captured from the wild. Based on AGDE-Dataset, we are able to propose a brand new scheme to automatically estimate grassland degradation, which mainly consists of two components. 1) Semantic segmentation: we design a deep neural network with an improved encoder-decoder structure to implement semantic segmentation of grassland images. In addition, we propose a novel Focal-Hinge Loss to alleviate the class imbalance of semantics in the training stage. 2) Degradation estimation: we provide the estimation of grassland degradation based on the results of semantic segmentation. Experimental results show that the proposed method achieves satisfactory accuracy in grassland degradation estimation.
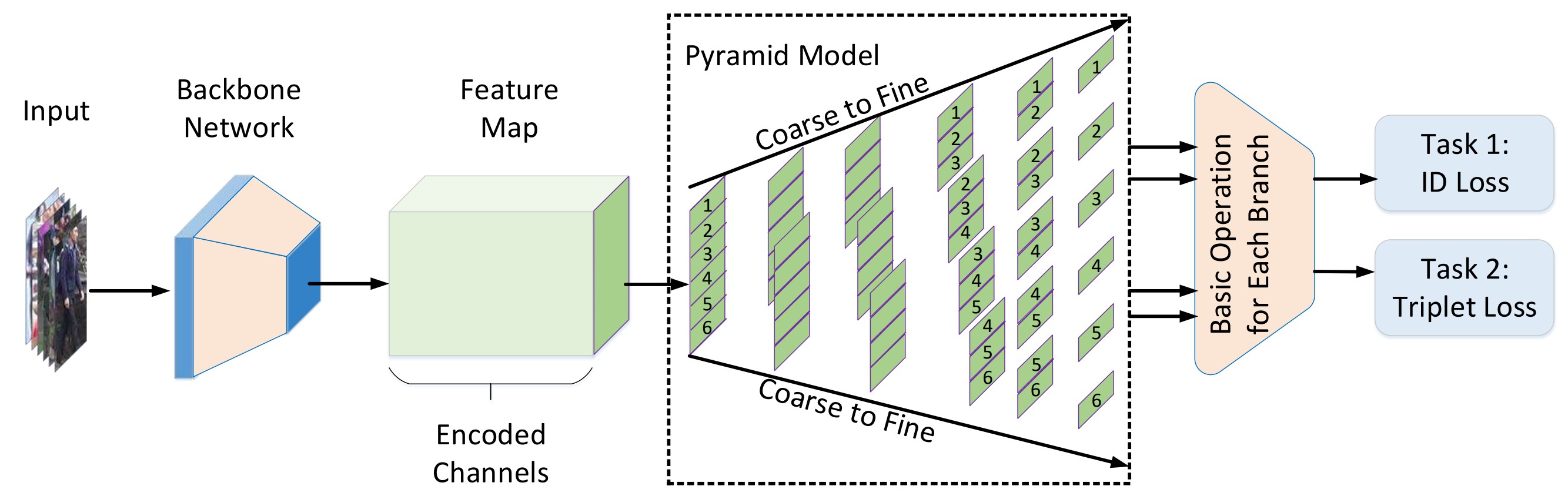
Pyramidal Person Re-IDentification via Multi-Loss Dynamic Training
Most existing Re-IDentification (Re-ID) methods are highly dependent on precise bounding boxes that enable images to be aligned with each other. However, due to the challenging practical scenarios, current detection models often produce inaccurate bounding boxes, which inevitably degenerate the performance of existing Re-ID algorithms. In this paper, we propose a novel coarse-to-fine pyramid model to relax the need of bounding boxes, which not only incorporates local and global information, but also integrates the gradual cues between them. The pyramid model is able to match at different scales and then search for the correct image of the same identity, even when the image pairs are not aligned. In addition, in order to learn discriminative identity representation, we explore a dynamic training scheme to seamlessly unify two losses and extract appropriate shared information between them. Experimental results clearly demonstrate that the proposed method achieves the state-of-the-art results on three datasets. Especially, our approach exceeds the current best method by 9.5% on the most challenging CUHK03 dataset.

A Winner-Take-All Strategy for Improved Object Tracking
Recently, numerous state-of-the-art learning schemes are proposed for object tracking. However, typically, most methods can only solve certain type of challenges but are less effective for the rest—no single tracker is perfect for all challenges. In this paper, a winner-take-all (WTA) strategy is exploited to select a winner tracker (considering both accuracy and efficiency) from a set of prevailing methods to tackle the current challenge, according to features extracted from the current environment and an efficiency factor. To achieve this, a structural regression model to characterize the trackers is trained on a public dataset. By incorporating the complementary abilities from multiple trackers, the diversity of the model is improved so that the WTA tracker can tackle various unpredictable difficulties. Since only one tracker is selected at any time, the average efficiency of the proposed model is also higher than that of complex trackers in the tracker set. The proposed WTA framework is tested on two benchmark datasets as well as several long sequences, and extensive experimental results illustrate that WTA can significantly improve both the performance and the efficiency.

A Unified Multi-Scenario Attacking Network for Visual Object Tracking
Existing methods of adversarial attacks successfully generate adversarial examples to confuse Deep Neural Networks (DNNs) of image classification and object detection, resulting in wrong predictions. However, these methods are difficult to attack models of video object tracking, because the tracking algorithms could handle sequential information across video frames and the categories of targets tracked are normally unknown in advance. In this paper, we propose a Unified and Effective Network, named UEN, to attack visual object tracking models. There are several appealing characteristics of UEN: (1) UEN could produce various invisible adversarial perturbations according to different attack settings by using only one simple end-to-end network with three ingenious loss function; (2) UEN could generate general visible adversarial patch patterns to attack the advanced trackers in the real-world; (3) Extensive experiments show that UEN is able to attack many state-of-the-art trackers effectively (e.g. SiamRPN-based networks and DiMP) on popular tracking datasets including OTB100, UAV123, and GOT10K, making online real-time attacks possible. The attack results outperform the introduced baseline in terms of attacking ability and attacking efficiency.